The Tracker team will be doing a codecamp this month. Among the subjects we will address is the IPC overhead of tracker-store, our RDF query service.
We plan to investigate whether a direct connection with our SQLite database is possible for clients. Jürg did some work on this. Turns out that due to SQLite not being MVCC we need to override some of SQLite’s VFS functions and perhaps even implement ourselves a custom page cache.
Another track that we are investigating involves using a custom UNIX domain socket and sending the data over in such a way that at either side the marshalling is cheap.
For that idea I asked Adrien Bustany, a computer sciences student who’s doing an internship at Codeminded, to develop three tests: A test that uses D-Bus the way tracker-store does (by using the DBusMessage API directly), a test that uses an as ideal as possible custom protocol and technique to get the data over a UNIX domain socket and a simple program that does the exact same query but connects to SQLite by itself.
Exposing a SQLite database remotely: comparison of various IPC methods
By Adrien Bustany
Computer Sciences student
National Superior School of Informatics and Applied Mathematics of Grenoble (ENSIMAG)
This study aims at comparing the overhead of an IPC layer when accessing a SQLite database. The two IPC methods included in this comparison are DBus, a generic message passing system, and a custom IPC method using UNIX sockets. As a reference, we also include in the results the performance of a client directly accessing the SQLite database, without involving any IPC layer.
Comparison methodology
In this section, we detail what the client and server are supposed to do during the test, regardless of the IPC method used.
The server has to:
- Open the SQLite database and listen to the client requests
- Prepare a query at the client’s request
- Send the resulting rows at the client’s request
Queries are only “SELECT” queries, no modification is performed on the database. This restriction is not enforced on server side though.
The client has to:
- Connect to the server
- Prepare a “SELECT” query
- Fetch all the results
- Copy the results in memory (not just fetch and forget them), so that memory pages are really used
Test dataset
For testing, we use a SQLite database containing only one table. This table has 31 columns, the first one is the identifier and the 30 others are columns of type TEXT. The table is filled with 300 000 rows, with randomly generated strings of 20 ASCII lowercase characters.
Implementation details
In this section, we explain how the server and client for both IPC methods were implemented.
Custom IPC (UNIX socket based)
In this case, we use a standard UNIX socket to communicate between the client and the server. The socket protocol is a binary protocol, and is detailed below. It has been designed to minimize CPU usage (there is no marshalling/demarshalling on strings, nor intensive computation to decode the message). It is fast over a local socket, but not suitable for other types of sockets, like TCP sockets.
Message types
There are two types of operations, corresponding to the two operations of the test: prepare a query, and fetch results.
Message format
All numbers are encoded in little endian form.
Prepare
Client sends:
| Size | Contents |
| 4 bytes | Prepare opcode (0x50) |
| 4 bytes | Size of the query (without trailing \0) |
| … | Query, in ASCII |
Server answers:
| Size | Contents |
| 4 bytes | Return code of the sqlite3_prepare_v2 call |
Fetch
Client sends:
| Size | Contents |
| 4 bytes | Fetch opcode (0x46) |
Server sends rows grouped in fixed size buffers. Each buffer contains a variable number of rows. Each row is complete. If some padding is needed (when a row doesn’t fit in a buffer, but there is still space left in the buffer), the server adds an “End of Page” marker. The “End of page” marker is the byte 0xFF. Rows that are larger than the buffer size are not supported.
Each row in a buffer has the following format:
| Size | Contents |
| 4 bytes | SQLite return code. This is generally SQLITE_ROW (there is a row to read), or SQLITE_DONE (there are no more rows to read). When the return code is not SQLITE_ROW, the rest of the message must be ignored. |
| 4 bytes | Number of columns in the row |
| 4 bytes | Index of trailing \0 for first column (index is 0 after the “number of columns” integer, that is, index is equal to 0 8 bytes after the message begins) |
| 4 bytes | Index of trailing \0 for second column |
| … | |
| 4 bytes | Index of trailing \0 for last column |
| … | Row data. All columns are concatenated together, and separated by \0 |
For the sake of clarity, we describe here an example row
100 4 1 7 13 19 1\0aaaaa\0bbbbb\0ccccc\0
The first 100 is the return code, in this case SQLITE_ROW. This row has 4 columns. The 4 following numbers are the offset of the \0 terminating each column in the row data. Finally comes the row data.
Memory usage
We try to minimize the calls to malloc and memcpy in the client and server. As we know the size of a buffer, we allocate the memory only once, and then use memcpy to write the results to it.
DBus
The DBus server exposes two methods, Prepare and Fetch.
Prepare
The Prepare method accepts a query string as a parameter, and returns nothing. If the query preparation fails, an error message is returned.
Fetch
Ideally, we should be able to send all the rows in one batch. DBus, however, puts a limitation on the message size. In our case, the complete data to pass over the IPC is around 220MB, which is more than the maximum size allowed by DBus (moreover, DBus marshalls data, which augments the message size a little). We are therefore obliged to split the result set.
The Fetch method accepts an integer parameter, which is the number of rows to fetch, and returns an array of rows, where each row is itself an array of columns. Note that the server can return less rows than asked. When there are no more rows to return, an empty array is returned.
Results
All tests are ran against the dataset described above, on a warm disk cache (the database is accessed several time before every run, to be sure the entire database is in disk cache). We use SQLite 3.6.22, on a 64 bit Linux system (kernel 2.6.33.3). All test are ran 5 times, and we use the average of the 5 intermediate results as the final number.
For the custom IPC, we test with various buffer sizes varying from 1 to 256 kilobytes. For DBus, we fetch 75000 rows with every Fetch call, which is close to the maximum we can fetch with each call (see the paragraph on DBus message size limitation).
The first tests were to determine the optimal buffer size for the UNIX socket based IPC. The following graph describes the time needed to fetch all rows, depending on the buffer size:
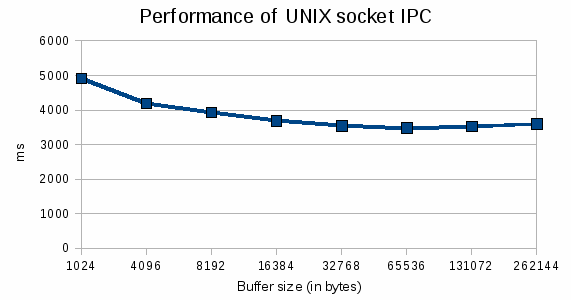
The graph shows that the IPC is the fastest using 64kb buffers. Those results depend on the type of system used, and might have to be tuned for different platforms. On Linux, a memory page is (generally) 4096 bytes, as a consequence buffers smaller than 4kB will use a full memory page when sent over the socket and waste memory bandwidth. After determining the best buffer size for socket IPC, we run tests for speed and memory usage, using a buffer size of 64kb for the UNIX socket based method.
Speed
We measure the time it takes for various methods to fetch a result set. Without any surprise, the time needed to fetch the results grows linearly with the amount of rows to fetch.
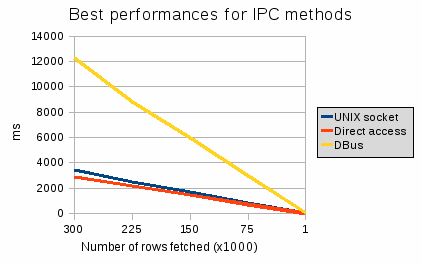
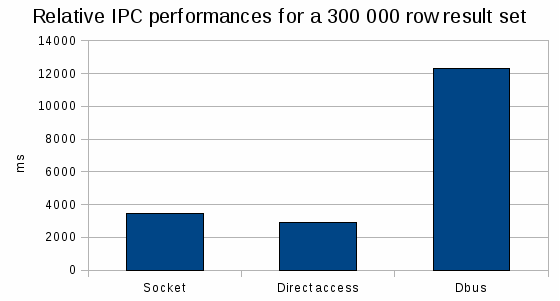
| IPC method | Best time |
| None (direct access) | 2910 ms |
| UNIX socket | 3470 ms |
| DBus | 12300 ms |
Memory usage
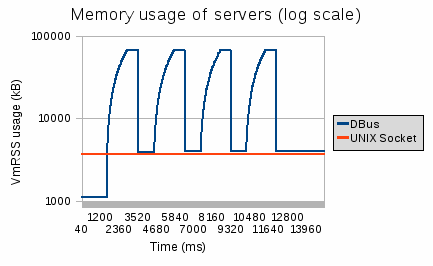
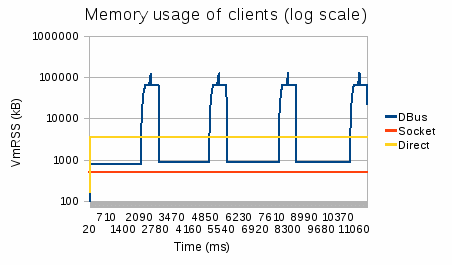
Memory usage varies greatly (actually, so much that we had to use a log scale) between IPC methods. DBus memory usage is explained by the fact that we fetch 75 000 rows at a time, and that it has to allocate all the message before sending it, while the socket IPC uses 64 kB buffers.
Conclusions
The results clearly show that in such a specialized case, designing a custom IPC system can highly reduce the IPC overhead. The overhead of a UNIX socket based IPC is around 19%, while the overhead of DBus is 322%. However, it is important to take into account the fact that DBus is a much more flexible system, offering far more features and flexibility than our socket protocol. Comparing DBus and our custom UNIX socket based IPC is like comparing an axe with a swiss knife: it’s much harder to cut the tree with the swiss knife, but it also includes a tin can opener, a ball pen and a compass (nowadays some of them even include USB keys).
The real conclusion of this study is: if you have to pass a lot of data between two programs and don’t need a lot of flexibility, then DBus is not the right answer, and never intended to be.
The code source used to obtain these results, as well as the numbers and graphs used in this document can be checked out from the following git repository: git://git.mymadcat.com/ipc-performance . Please check the various README files to see how to reproduce them and/or how to tune the parameters.
Great post!
Maybe it would be a good idea to write a dbus api exactly for these bulk-data transmissions. This api would use dbus for service discovery, then transparently forward the data through unix sockets.
This is similar to the way “bluetooth over wifi” works. Bluetooth is used for discovery / handshakes, then wifi is used for bulk data transfer.
From ZDNet:
“Devices will use the regular low-power Bluetooth radios to recognize each other and establish connections,” writes ZDNet’s Rik Fairlie. “If they need to transfer a large file, they will be able to turn on their Wi-Fi radios, then turn them off to save power after finishing the transfer.”
(http://www.zdnet.com/blog/soho-networking/bluetooth-and-wi-fi-combo-could-yield-faster-bulk-data-transfers/139?p=139)
What do you think?
Can’t DBUS be changed to do progressive message decoding? Or even support a streaming mode? This would solve most of your concerns while improving DBUS at the same time.
“The real conclusion of this study is: if you have to pass a lot of data between two programs and don’t need a lot of flexibility, then DBus is not the right answer, and never intended to be.”
I’m surprised that someone still needed a study to prove that, I thought it was already common knowledge…
The recommended way to get both the flexibility of D-Bus and the bandwidth of raw sockets is to use the Prepare() call to set up a socket from which the data can can be transferred.
*That* should be the conclusion ;)
This is why gvfs used dbus for everything except for the actual file contents. File contents is instead sent via a custom binary protocol over a pipe that is passed from the gvfs daemon to the client as a result of the open() dbus method.
For gvfs the code handling the fd passing involved is a bit nasty. However, recent versions of dbus has fd passing built in, which should make this very clean and nice.
@Kall Vahlman: Yes we already knew that D-Bus wasn’t fit for large transfers. The experiment was, however, done to see how well such a custom protocol and Unix domain socket would fit with Tracker’s tracker-store RDF query service, and how fast we could make it given SQLite’s limitations (sqlite_value_bytes is rather slow); not to prove that D-Bus is slow at large transfers, everybody indeed already knows that. If it were files then we’d of course use D-Bus’s FD passing mechanisms. Your so-called *real conclusion* about Prepare() is precisely why we’ve split the experiment’s socket’s protocol up in a Prepare() and Fetch(), so that we could easily adapt the solution to something like this afterward.
@Alexander Larsson: When you have a file descriptor then using D-Bus’s FD passing is of course the preferred way. In our case we have sqlite3_step(), though. When (and if) we do replace D-Bus for the transfer of query’s result-data we wont replace D-Bus for the other IPC-needs either, of course. sqlite3_step() overwrites the previous pointers to the cell data, so we’d have to copy if we’d wanted to pass info about shared memory, or something. Causing a lot of memory usage in the server. So instead, we opted for sending it over in chunks of 64k.
@Rodrigo Kumpera, Rodrigo Kumpera & tvst (streaming-mode suggestions): Sounds like a good idea to me.
Perhaps the problems referenced in the beginning are a good indication that it might not be the real thing to make sqlite into a multi-user, multi-client database. Its not exactly intended to be that…
@Andres Freund: That wasn’t the point of this experiment, though. Note that with shared-cache and read_uncommitted mode you can get pretty far with SQLite. Although we’d need a bit more, indeed. SQLite is a design decision for Tracker and we’re of course well aware of SQLite’s limitations. Long term we might consider a database engine like Firebird, but this isn’t being planned at this moment (not for the 0.9 series of Tracker).
pvanhoof:
A file descriptor is only a pipe2() call away. You just create one, send the reading side to the client and then write out the data on the writing side. Additionally it might be possible to get less copying if you use vmsplice() to write to the buffer.
I don’t understand what sqlite3_step overwriting data has to do with anything, this would obviously copy the data just like your custom socket protocol.
@Alexander Larsson: Ah, yes, with a pipe it would be possible to use a FD indeed. You’re right about that. I guess that, at least on Linux, pipe will give similar results as a unix domain socket..? Under the hood I expect that the kernel deals with both the same way. I need to look up how vmsplice works; splicing user pages into a pipe sounds good, yes.
If you want to increase the performance 5-10 times, use Tokyo Cabinet and not SQLite to actually get the data. But if you want maximum performance and don’t care that much about RAM, then keeping the data in RAM can easily be 10-50 times faster than any database.
@Aigars Mahinovs: Apples and oranges: Tokyo Cabinet is a key-value store, not a database with an SQL front end. We translate the SPARQL query into SQL, so we need the expressiveness of such an SQL front end (Tokyo Cabinet’s query expressiveness isn’t sufficient, no). With a key-value store would implementing a SPARQL endpoint be too difficult to do in a well performing way. Note that at some point we considered Tokyo Cabinet for our FTS needs. But because sqlite-fts was already well integrated with SQLite, we opted for this instead. When somebody finds the time to implement a virtual table for Tokyo Cabinet in SQLite, then we might reconsider this indeed (but only for FTS, and note that also for FTS we already have a few specific needs. We would like snippet support, for example).
Keeping all things in RAM also isn’t an option, the target hardware is a mobile device with only a few hundred megabytes of RAM. Not yet gigabytes. But maybe in future this will be an option? BTW, if you have the right indexes in your tables then aren’t on-disk databases going to perform bad either.
In any case, the storage of the data also wasn’t really the point of the experiment. But we did want a realistic measurement, not a sort of “everything-is-in-RAM-dream-come-true”; that’s not useful to measure. Particularly sqlite_value_bytes(), sqlite_value_text() and the memcpy on its results had to be realistic for this experiment.
“On Linux, a memory page is (generally) 4096 bytes, as a consequence buffers smaller than 4kB will use a full memory page when sent over the socket and waste memory bandwidth.”
Say what?
Only the parts actually written/read will be copied — the kernel pretty much just does a memcpy(). The page size is irrelevant.
Btw, copying (with memcpy or similar) is practically free as long as everything stays within the CPU cache(s). If you are moving big amounts of data around you’d rather not stream through it more than once because if it is big it will /not/ fit in cache. The CPU might be able to 1) do smart prefetching, 2) have a sensible write allocation policy for its cache(s), 3) not blow the cache(s) entirely but retain most of the non-copied data. I don’t believe we’re quite there yet ;)
Using vmsplice() (or mmap() tricks) or copying smaller chunks that each fit in the cache ought to be good ideas. You also don’t have the 2x spike in memory use around the copying (1x for the sender, 1x for the receiver).
@Peter Lund: Interesting point, I admit I’m not totally aware of what happens at kernel level. Cachegrind does give some cache hit/miss numbers, I should maybe have a look at them for various buffer sizes.
You might want to read the updated version of the report: http://blogs.gnome.org/abustany/2010/05/20/ipc-performance-the-return-of-the-report/
It does include a new IPC method, and also a report about my vmsplice experiment.